
单因子指数法
单因子指数法是利用实测数据和标準对比分类,选取水质最差的类别即为评价结果。
基本介绍
- 中文名:单因子指数法
- 类型:方法
- 类别:指数法
- 原理:利用实测数据和标準对比分类
方法简介及步骤
计算某一评价指标的污染指数公式为:
单项指标污染指数:
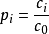
或者
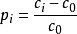
某断面综合污染指数:
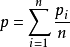
式中 Pi——某一评价指标的相对污染值
Ci——某一评价指标的实测浓度值
Co——某一评价指标的最高允许标準值
P——某断面的污染指数
n——某断面内测点数
计算单项参数溶解氧(DO)来说,,其只值应随浓度增大而减小,因此它的计算式:
2–4
式子是根据国家及有关部门颁布的水环境质量标準,以L4作为溶解氧最低浓度标準值,以C i≥8作为河流未受污染时的情况.
对于评价参数pH ,由于它的Ci浓度值为7.0时,表明河流水质状况良好,Ci过高或过低均表示不同性质的污染。计算公式为:
2–5
式中:—— pH 的最高浓度标準值
—— pH 的最低浓度标準值
主成分分析方法
地理环境是多要素的複杂系统,在我们进行地理系统分析时,多变数问题是经常会遇到的。变数太多,无疑会增加分析问题的难度与複杂性,而且在许多实际问题中,多个变数之间是具有一定的相关关係的。因此,我们就会很自然地想到,能否在各个变数之间相关关係研究的基础上,用较少的新变数代替原来较多的变数,而且使这些较少的新变数儘可能多地保留原来较多的变数所反映的信息?事实上,这种想法是可以实现的,本节拟介绍的主成分分析方法就是综合处理这种问题的一种强有力的方法。
第一节 主成分分析方法的原理
主成分分析是把原来多个变数化为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。假定有n个地理样本,每个样本共有p个变数描述,这样就构成了一个n×p阶的地理数据矩阵:
如何从这幺多变数的数据中抓住地理事物的内在规律性呢?要解决这一问题,自然要在p维空间中加以考察,这是比较麻烦的。为了克服这一困难,就需要进行降维处理,即用较少的几个综合指标来代替原来较多的变数指标,而且使这些较少的综合指标既能儘量多地反映原来较多指标所反映的信息,同时它们之间又是彼此独立的。那幺,这些综合指标(即新变数)应如何选取呢?显然,其最简单的形式就是取原来变数指标的线性组合,适当调整组合係数,使新的变数指标之间相互独立且代表性最好。
如果记原来的变数指标为x1,x2,…,xp,它们的综合指标——新变数指标为x1,x2,…,zm(m≤p)。则
在(2)式中,係数lij由下列原则来决定:
(1)zi与zj(i≠j;i,j=1,2,…,m)相互无关;
(2)z1是x1,x2,…,xp的一切线性组合中方差最大者;z2是与z1不相关的x1,x2,…,xp的所有线性组合中方差最大者;……;zm是与z1,z2,……zm-1都不相关的x1,x2,…,xp的所有线性组合中方差最大者。
这样决定的新变数指标z1,z2,…,zm分别称为原变数指标x1,x2,…,xp的第一,第二,…,第m主成分。其中,z1在总方差中占的比例最大,z2,z3,…,zm的方差依次递减。在实际问题的分析中,常挑选前几个最大的主成分,这样既减少了变数的数目,又抓住了主要矛盾,简化了变数之间的关係。
从以上分析可以看出,找主成分就是确定原来变数xj(j=1,2,…,p)在诸主成分zi(i=1,2,…,m)上的载荷lij(i=1,2,…,m;j=1,2,…,p),从数学上容易知道,它们分别是x1,x2,…,xp的相关矩阵的m个较大的特徵值所对应的特徵向量。
第二节 主成分分析的解法
主成分分析的计算步骤
通过上述主成分分析的基本原理的介绍,我们可以把主成分分析计算步骤归纳如下:
(1)计算相关係数矩阵
在公式(3)中,rij(i,j=1,2,…,p)为原来变数xi与xj的相关係数,其计算公式为
因为R是实对称矩阵(即rij=rji),所以只需计算其上三角元素或下三角元素即可。
(2)计算特徵值与特徵向量
首先解特徵方程|λI-R|=0求出特徵值λi(i=1,2,…,p),并使其按大小顺序排列,即λ1≥λ2≥…,≥λp≥0;然后分别求出对应于特徵值λi的特徵向量ei(i=1,2,…,p)。
(3)计算主成分贡献率及累计贡献率
一般取累计贡献率达85-95%的特徵值λ1,λ2,…,λm所对应的第一,第二,……,第m(m≤p)个主成分。
(4)计算主成分载荷
由此可以进一步计算主成分得分:
第三节 主成分分析套用实例
主成分分析实例
对于某区域地貌-水文系统,其57个流域盆地的九项地理要素:x1为流域盆地总高度(m)x2为流域盆地山口的海拔高度(m),x3为流域盆地周长(m),x4为河道总长度(km),x5为河
表2-14 某57个流域盆地地理要素数据
道总数,x6为平均分叉率,x7为河谷最大坡度(度),x8为河源数及x9为流域盆地面积(km)的原始数据如表2-14所示。张超先生(1984)曾用这些地理要素的原始数据对该区域地貌-水文系统作了主成分分析。下面,我们将其作为主成分分析方法在地理学研究中的一个套用实例介绍给读者,以供参考。
表2-15相关係数矩阵
(1)首先将表2-14中的原始数据作标準化处理,由公式(4)计算得相关係数矩阵(见表2-15)。
(2)由相关係数矩阵计算特徵值,以及各个主成分的贡献率与累计贡献率(见表2-16)。由表2-16可知,第一,第二,第三主成分的累计贡献率已高达86.5%,故只需求出第一,第二,第三主成分z1,z2,z3即可。
表2-16 特徵值及主成分贡献率
(3)对于特徵值λ1=5.043,λ2=1.746,λ3=0.997分别求出其特徵向量e1,e2,e3,并计算各变数x1,x2,……,x9在各主成分上的载荷得到主成分载荷矩阵(见表2-17)。
表2-17 主成分载荷矩阵
从表2-17可以看出,第一主成分z1与x1,x3,x4,x5,x8,x9有较大的正相关,这是由于这六个地理要素与流域盆地的规模有关,因此第一主成分可以被认为是流域盆地规模的代表:第二主成分z2与x2有较大的正相关,与x7有较大的负相关,而这两个地理要素是与流域切割程度有关的,因此第二主成分可以被认为是流域侵蚀状况的代表;第三主成分z3与x6有较大的正相关,而地理要素x6是流域比较独立的特性——河系形态的表征,因此,第三主成成可以被认为是代表河系形态的主成分。
以上分析结果表明,根据主成分载荷,该区域地貌-水文系统的九项地理要素可以被归为三类,即流域盆地的规模,流域侵蚀状况和流域河系形态。如果选取其中相关係数绝对值最大者作为代表,则流域面积,流域盆地出口的海拔高度和分叉率可作为这三类地理要素的代表,利用这三个要素代替原来九个要素进行区域地貌-水文系统分析,可以使问题大大地简化。
二、内梅罗水质指数污染
表1 内梅罗水质指数污染等级划分标準
P | <1 | 1~2 | 2~3 | 3~5 | >5 |
水质等级 | 清洁 | 轻污染 | 污染 | 重污染 | 严重污染 |
表2 地表水环境质量标準(GB3838—2002) 单位:mg/L
序 号 | 项 目 | V类标準值 |
1 | 水温(℃) | — |
2 | PH值(无量纲) | 6—9 |
3 | 溶解氧 ≥ | 2 |
4 | 高锰酸盐指数 ≤ | 15 |
5 | 化学需氧量 ≤ | 40 |
6 | 五日生化需氧量 ≤ | 10 |
7 | 氨氮 ≤ | 2.0 |
8 | 总磷 ≤ | 0.4 |
9 | 总氮 ≤ | 2.0 |
10 | 铜 ≤ | 1.0 |
11 | 锌 ≤ | 2.0 |
12 | 氟化物 ≤ | 1.5 |
13 | 硒 ≤ | 0.02 |
14 | 砷 ≤ | 0.1 |
15 | 汞 ≤ | 0.001 |
16 | 镉 ≤ | 0.01 |
17 | 铬(六价) ≤ | 0.1 |
18 | 铅 ≤ | 0.1 |
19 | 氰化物 ≤ | 0.2 |
20 | 挥发酚 ≤ | 0.1 |
21 | 石油类 ≤ | 1.0 |
22 | 硫化物 ≤ | 1.0 |
23 | 粪大肠菌群(个/L) ≤ | 40000 |
表3 水质评价计算方法 |
单因子污染指数 | Pi = Ci/ Si | Ci——第i项污染物的监测值; Si——第i项污染物评价标準值; | |
溶解氧指数 | Cf——对应温度T时的饱和溶解氧浓度; Ci——溶解氧浓度监测值; Si——溶解氧评价标準值; | ||
pH指数 | pHi——pH监测值; pHS,min——评价标準值的下限; pHS,max ——评价标準值的上限; | ||
污染物超标倍数 | Ci ——第i项污染物的监测值; C0 ——第i项污染物评价标準值; | ||
内梅罗指数 | Pmax ——单因子污染指数的最高值; Pi ——第i项污染物的污染指数; n ——参与评价污染物的项数; | ||
常用的客观赋权法之一:熵值法
熵是资讯理论中测度一个系统不确定性的量。信息量越大,不确定性就越小,熵也越小,反之,信息量越小,不确定性就越大,熵也越大。熵值法主要是依据各指标值所包含的信息量的大小,利用指标的熵值来确定指标权重的。熵值法的一般步骤为:
(1)、对决策矩阵作标準化处理,得到标準化矩阵,并进行归一化处理得:
(2)、计算第个指标的熵值:。其中。
(3)、计算第个指标的差异係数。对于第个指标,指标值的差异越大,对方案评价的作用越大,熵值越小,反之,差异越小,对方案评价的作用越小,熵值就越大。因此,定义差异係数为:。
(4)、确定指标权重。第个指标的权重为:。
效益型和成本型指标的标準化方法
对于效益型(正向)指标和成本型(逆向)指标,由于这两者是最常见并且使用最广泛的指标,所以,对这两种指标标準化处理的方法也最多,一般的处理方法有:
1. 极差变换法
该方法即在决策矩阵中,对于效益型指标,令
=
对于成本型指标,令
=
则得到的矩阵称为极差变换标準化矩阵。其优点为经过极差变换后,均有,且各指标下最好结果的属性值,最坏结果的属性值。该方法的缺点是变换前后的各指标值不成比例。
2. 线性比例变换法
即在决策矩阵中,对于效益型指标,令
=
对成本型指标,令
=
或
=
则矩阵称为线性比例标準化矩阵。该方法的优点是这些变换方式是线性的,且变化前后的属性值成比例。但对任一指标来说,变换后的和不一定同时出现。
3. 向量归一化法
即在决策矩阵中,对于效益型指标,令
对于成本型指标,令
则矩阵称为向量归一标準化矩阵。显然,矩阵的列向量的模等于1,即。该方法使,且变换前后正逆方向不变,缺点是它是非线性变换,变换后各指标的最大值和最小值不相同。
4. 标準样本变换法
在中,令
其中,样本均值,样本均方差,则得出矩阵,称为标準样本变换矩阵。经过标準样本变换之后,标準化矩阵的样本均值为,方差为。
5. 等效係数法
对成本型指标,令
=
该方法的优点是变换前后的指标值成比例,缺点是各指标下方案的最好与最差指标值标準化后不完全相同。
另外,关于效益型指标的标準化处理还有:
=
关于成本型指标的标準化处理还有:
=
固定型指标的标準化方法
对于固定型指标,若设为给定的固定值,则标準化处理的方法主要有以下几种,即令
或
或
或
(4.15)式的特点是各最优属性值标準化后的值均为1,而各最差属性的值标準化后的值不统一,即不一定都为0。
若设和分别是人为规定的最优方案和最劣方案,在该情形下,还给出了效益型、成本型和固定型指标的新的标準化方法。
对效益型和成本型,有:
对固定型指标则有:
区间型指标的标準化方法
对区间型的指标,其指标标準化处理的方法主要有以下几式:
设,令
或令
显然,还可以简化为:
或令
或令
其中,是指给定的某个固定区间,即属性值越接近该区间越好。
偏离型指标的标準化方法
对越来越偏离某值越好的偏离性指标,一般有如下标準化公式:
或令
(对都有)
或令
偏离型指标是与固定型指标相对立的一种指标类型,它的公式使用可以用固定型指标的公式改造,但在使用时要注意其公式的适用範围。
偏离区间型指标的标準化方法
对偏离区间型指标,有如下标準化的方法:
令
或令
或令
其中,是某个固定区间,属性值越偏离该区间越好。偏离区间型指标是与区间型指标相对立的一种指标类型。