
语言基频识别
汉语是一种有调语言,其声调具有辨意的作用。 声调是重要的声学参数,在语音识别、语音合成和分析处理套用中, 都有重要的意义。声调是由调值和调型组成的,调值由基颇数值决定,调型由调值的走向决定。基频是语言信号的一个重要参数。语言基频识别就是将语音信号的基频提取出来,以彩色动态图形的方式显示其大小和变化形状。
基本介绍
- 中文名:语言基调识别
- 外文名:language fundamental frequency recognition
- 套用:语言识别、语音合成、分析处理
- 声调:重要声学参数,由调值和调型组成
- 常用算法:自相关、平行处理法、倒谱法等
- 套用学科:计算机科学、电子科学、语言文学
简介
定义
汉语是一种有调语言,其声调具有辨意的作用。声调是重要的声学参数,在语音识别、语音合成和分析处理套用中,都有重要的意义。声调是由调值和调型组成的,调值由基频数值决定,调型由调值的走向决定。基频是语言信号的一个重要参数。在声码器和各种语言信号处理系统中一般都具有提取基频的基本部件。
语言基频识别就是将语音信号的基频提取出来,以彩色动态图形的方式显示其大小和变化形状。
目前普遍地对在噪声的背底中增强语言信号感兴趣,也提出了一些减低噪声增强语言信号的方法,例如频谱相减方法、基频跟蹤方法、自相关方法、线性滤波方法、自适应滤波方法等等。它们对减小噪声提高信噪比都有一定的效果。然而其中的一些方法,如自相关、基频跟蹤以及一种自适应滤波等都需要先测得基频参数。
研究背景
在现有的汉语语音识别系统中,声调信息并未得到充分利用,随着汉语语音识别技术的进一步发展,声调研究成为识别技术突破的重要方向;在语音合成研究中,目前合成自然度不高的一个重要因素是韵律规则的不完善,而汉语韵律规律的核心问题就是声调规律。因此为了能在语音识别和合成中充分、有效的利用声调信息,必须对连续语音中汉语声调的特点进行深入的研究,并从声调特徵的提取、声调的建模、连续语音中声调变化规律的获取以及连续语音中声调的识别这四个方面对连续语音中的汉语声调进行深入研究。而基频曲线是汉语声调的最本质特徵,因而基频的提取是声调研究的基础。
常用基频提取算法
目前,常用的基频提取的算法大致有四种:自相关算法、平行处理法、倒谱法和简化逆滤波法。
自相关算法
自相关算法是利用语音信号在发浊音时的周期性来检验音调的周期的算法。对于确定性信号,自相关函式定义为:
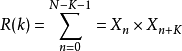
式中Xn是用採样频率f,对连续信号X(t)进行採样后得到的离散信号,而在对语言信号作自相关处理时.总是将语言信号X,分成若干帧,式中的N是帧的长度,K=0,1,2,...2/3N
如果信号序列是周期性的,其自相关函式也是同周期性的。并且自相关函式是偶函式,R(0)具有最大值。为了避免音调周期性和共振峰周期性混在一起,需要对语音信号进行预处理,从而去掉声道回响的影响。常用的预处理方法是“中心削波”技术.自相关算法的关键在于确定中心削波电平和自相关数据的点数。
中心削波电平与语音信号和环境噪音电平有关,一般取语音段最大幅度的一个固定百分数值,低于削波电平的信号输出为零。自相关数据的点数至少要大于音调周期的两倍,同时要儘可能地小以保证语音信号的短时性。
平行处理法
平行处理法是一种比较成功的音调检测的时域方法.语调信号通过略去与音调检测无关的信息而保留住信号的周期性的预处理后形成一系列脉冲,由平行的一些简单的检测器估计音调周期,在后处理器部分对这几个估值作逻辑组合,输出估计的正确周期。
倒谱法
倒谱法,是一种有效的频域方法,特别是对于无噪语音.倒谱法是基于声道的激励一调製模型,信号的倒谱是其功率的对数的傅立叶变换。
简化逆滤波法
简化逆滤波法,先降低语音信号採样率,抽取其模型参数,用这些参数对原信号进行逆滤波得出音源序列,最后求出该序列的峰值位置,从而求得音调周期。
简化基频提取算法
算法要求在低成本的硬体设备上,保证系统的实时性和準确性。因此,算法必须简单,而且要满足能够提取从普通成年男子的低频90Hz到儿童的高频450Hz的基颇。因为元音是汉语音调信息的主要携带者,元音主要分部在低频部分。所以只需採用4kHz的採样率。虽然平行处理法是一种不错的音调检测的时域方法,算法比较简单,但是,它同简化逆滤波算法一样都涉及到增加硬设备的问题,实现起来有特殊的要求,增加了成本。倒谱法在採用无噪语音时,性能很好,而存在加性噪声时其性能就会急剧恶化,并且该算法要经过傅立叶变换,运算量大,比较複杂,对于实时系统的实现有一定的困难。所以选用了一种简化的自相关算法。
自相关算法的关键在于确定中心削波电平和自相关数据的点数.中心削波电平与语音信号和环境噪音有关.藉助于中心削波可以消除语音信号的低幅度部分,但是,如果削波电平过低就起不到简化数值的目的,而削波电平太高又会破坏基频的周期性。
所以,採用语音信号峰值幅度的68.5%作为中心削波电平。自相关数据点应至少包括两个基颇周期。由于採用4kHz的採样率,取自相关数据的点数为120,从理论上讲,本算法可估计的频率範围可以达到最低66.7Hz,最高2kHz。具体算法的流程如下: 算法流程
算法流程
算法流程这种算法,从採样到基频提取,一直到图形的显示,可以实时地完成。
基于语音基频的性别识别方法
性别识别是语音信号处理中一个很重要的课题,他与语音识别、说话人识别、语音通信等都有很大的联繫。在语音识别和说话人识别实验中发现,事先知道说话人性别时所得到的正确识别率要比不知道说话人性别时高。在语音通信中,可以基于性别识别建立性别有关的语音特徵参数提取方案,减少特徵参数的维数,减少传输频宽。由此可见性别识别是语音识别研究中的一个重要问题,具有重要意义。
基音频率是性别识别最重要的判别依据。他反映了说话人发浊音时的声带振动频率。一般而言,男声的基音频率分布範围为0~200Hz,女声的基音频率分布範围为200~500Hz。因此,準确而可靠地估计基音周期对于说话人性别识别非常重要。
特徵提取方法
基音频率提取包括基音频率候选估计和后处理两个必要步骤。基音频率候选估计法主要有两类:时域估计法和变换域估计法。常用的时域估计方法有自相关函式法和平均幅度差函式法等;变换域方法有频域法和倒谱域法等。
採用归一化幅度差平方和函式法(sumofmagnitudedifferencesquarefunction,SMDSF)来进行基音周期候选估计,并利用viterbi算法进行后处理,快速、準确的提取基音频率。採取后处理的目的是使用基音周期全局的信息,纠正基音周期的局部错误,通过Viterbi算法可以找到一个最优的基音周期序列,使得发生基音周期误判错误的损失最小。
系统流程描述
利用幅度差平方和函式方法提取训练及测试语音所有帧的基音频率,分别基于男女训练集特徵档案利用EM参数估计法建立男女两个高斯混合模型,然后利用已训练好的两个模型分别对测试集中语音档案计算两个后验机率值,后验机率值大的性别类别即为该测试语音档案的性别类型,最后统计整个测试集的正确率。