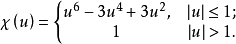稳健回归
稳健回归(robust regression)是统计学稳健估计中的一种方法,其主要思路是将对异常值十分敏感的经典最小二乘回归中的目标函式进行修改。经典最小二乘回归以使误差平方和达到最小为其目标函式。因为方差为一不稳健统计量,故最小二乘回归是一种不稳健的方法。不同的目标函式定义了不同的稳健回归方法。常见的稳健回归方法有:最小中位平方(least median square;LMS)法、M估计法等。
基本介绍
- 中文名:稳健回归
- 外文名:robust regression
- 所属学科:数学统计学
- 相关概念:稳健估计、回归模型等
基本介绍
稳健回归(robust regression)是将稳健估计方法用于回归模型,以拟合大部分数据存在的结构,同时可识别出潜在可能的离群点、强影响点或与模型假设相偏离的结构。当误差服从常态分配时,其估计几乎和最小二乘估计一样好,而最小二乘估计条件不满足时,其结果优于最小二乘估计。
稳健性测度指标
稳健性测度常用影响函式IF(influence function)及其扩展概念和崩溃点BP(breakdown point)。
影响函式
也称影响曲线(influence curve),它表示给出分布为F的一个(大)样本,在任意点x
处加入一个额外观测后对统计量T的(近似或标準化的)影响。如x以1-δ(o≤δ≤1)的机率来自于既定分布F,则其来自于另一个任意污染分布△x的机率为δ,此时的混合分布为:
处加入一个额外观测后对统计量T的(近似或标準化的)影响。如x以1-δ(o≤δ≤1)的机率来自于既定分布F,则其来自于另一个任意污染分布△x的机率为δ,此时的混合分布为:
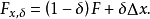
统计量T的影响函式就定义为:
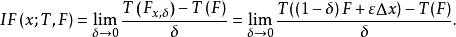
粗略地说,影响函式IF(x;T,F)是统计量T在一个既定分布F下的一阶导数,其中点x是有限维数的机率分布空间的坐标。如果某个统计量的IF有界,我们就称此统计量具有极微小稳健性。从IF推导出的还有“过失误差敏感度”GES(gross error sensitivity)γ*,它作为主要的局部稳健性尺度,可用以度量固定大小的极微小污染对统计量导致的最大偏差,即F的微小扰动下T的稳定性。如果一个稳健统计量的渐近偏差其上界是有限的,即γ*(T,F)有界,此时称T满足B-robust(B表示偏差bias);另外一个从IF推导出的概念是IF的L2範数,即T的渐近方差 ,可作为基本的估计效率尺度。这两个範数都依赖于F,于是可视之为新的泛函,其微小变化下的稳定性(经恰当的标準化后)可由“偏差改变函式”CBF(change of bias function或change of biascurve)和“方差改变函式”CVF(change of variance function或change of variance curve)和“方差改变函式”CVF(change of variance function或change of variance curve)来度量。这两个函式的上确界範数又可以作为简单的总结量,分别称为“偏差改变敏感度”CBS(change of bias sensitivity)和“方差改变敏感度”CVS(change of variance sensitivity)。如果CVS有界,可称T满足V-robust(V表示方差variance)。从概念上讲.V-robust要强于B-robust。
,可作为基本的估计效率尺度。这两个範数都依赖于F,于是可视之为新的泛函,其微小变化下的稳定性(经恰当的标準化后)可由“偏差改变函式”CBF(change of bias function或change of biascurve)和“方差改变函式”CVF(change of variance function或change of variance curve)和“方差改变函式”CVF(change of variance function或change of variance curve)来度量。这两个函式的上确界範数又可以作为简单的总结量,分别称为“偏差改变敏感度”CBS(change of bias sensitivity)和“方差改变敏感度”CVS(change of variance sensitivity)。如果CVS有界,可称T满足V-robust(V表示方差variance)。从概念上讲.V-robust要强于B-robust。
崩溃点
崩溃点是一个全局稳健性尺度。其起初的定义由Hodges针对于单变数情况下位置参数的估计提出,后由Hampel将其推广到更一般情形,回归分析中相对较为实用的概念是Donoho和Huber所提出的它在有限样本条件下的表达:

常见稳健回归方法
稳健回归估计主要包括基于似然估计的M类、基于残差顺序统计最某些线性变换的L类、基于残差秩次的R类及其广义估计和一些高崩溃点HBP(high breakdown point)方法。
R估计
R估计是Jackel等学者提出一种非参数回归方法。该方法不将残差取平方,而是将残差的秩次的某种函式作为离群点的降权函式引入估计模型,这样可以减小离群点对估计量的影响,从而达到稳健性要求。
R估计函式如下定义:
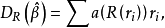
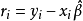

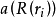
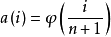

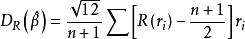
HBP回归
常见的高崩溃点回归包括最小平方中位数(least median of squares)LMS回归、LTS(least trimmed squares)回归、S估计、GS估计、MM估计和 估计等。
估计等。
LMS与LTS估计
考虑到经典LS估计的目标函式定义为使得各残差的平方和最小也就相当于使各残差平方的算术均数最小,而算术均数对于偏离常态分配的情况其估计显然是不稳健的,但在此情况下中位数却非常稳健,于是将LS估计的目标函式改为使各残差平方的中位数最小,得到的“最小平方中位数”估计应该是稳健的,即定义:
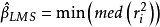
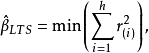
式中的 由各残差从小到大排序后得到,即
由各残差从小到大排序后得到,即 。可以注意到该估计方法的崩溃点大小与h值的设定有关,其值越小,崩溃点越大,一般情况下取为(3n+p+1)/4时可兼顾崩溃点与估计效率。这两种估计方法刚提出时均採用的是重複抽样算法(resampling algorithm),之后的讨论和改进主要是考虑如何在儘量减少运算量的情况下得到近似或确切的估计值,如基于Chebyshev拟合的对偶型线性规划算法寻找可行解集(feasible set algorithm)等,目前多採用的是改进的快速算法。
。可以注意到该估计方法的崩溃点大小与h值的设定有关,其值越小,崩溃点越大,一般情况下取为(3n+p+1)/4时可兼顾崩溃点与估计效率。这两种估计方法刚提出时均採用的是重複抽样算法(resampling algorithm),之后的讨论和改进主要是考虑如何在儘量减少运算量的情况下得到近似或确切的估计值,如基于Chebyshev拟合的对偶型线性规划算法寻找可行解集(feasible set algorithm)等,目前多採用的是改进的快速算法。
遗憾的是由于其残差分布未知,所以其估计值的标準误没有显解式,此情况下可以考虑使用Bootstrap方法作统计推断。而多数情况下由于这两种估计具有较高的崩溃点,它被用来作离群点诊断或得到其他稳健估计方法的初值。例如提出这类方法的Rousseeuw等人建议可以在LTS或LMS估计基础上进行“再加权最小二乘估计”(reweighted least sum of squares),即弃去那些残差较大的点,对剩余数据进行普通最小二乘估计,或等价地将权重定义为:

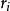
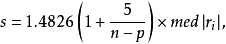
S估计
该法也由Rousseeuw和Yohai提出,所谓的S估计,它对回归係数的选择使得方程