)")
遗传算法(生物进化过程的计算模型)
遗传(生物进化过程的计算模型)一般指本词条
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜寻最优解的方法。遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特徵的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头髮的特徵是由染色体中控制这一特徵的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很複杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并藉助于自然遗传学的遗传运算元(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
基本介绍
- 中文名:遗传算法
- 外文名:Genetic Algorithm
- 基本概念:是一类借鉴生物界的进化规律
- 基本运算:初始化
- 特点:对于各种通用问题都可以使用
运算过程
遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜寻方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函式连续性的限定;具有内在的隐并行性和更好的全局寻优能力;採用机率化的寻优方法,能自动获取和指导最佳化的搜寻空间,自适应地调整搜寻方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地套用于组合最佳化、机器学习、信号处理、自适应控制和人工生命等领域。它是现代有关智慧型计算中的关键技术。
对于一个求函式最大值的最佳化问题(求函式最小值也类同),一般可以描述为下列数学规划模型:
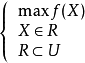
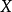
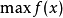

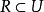
遗传算法也是计算机科学人工智慧领域中用于解决最最佳化的一种搜寻启发式算法,是进化算法的一种。这种启发式通常用来生成有用的解决方案来最佳化和搜寻问题。进化算法最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。遗传算法在适应度函式选择不当的情况下有可能收敛于局部最优,而不能达到全局最优。遗传算法的基本运算过程如下:
a)初始化:设定进化代数计数器t=0,设定最大进化代数T,随机生成M个个体作为初始群体P(0)。
b)个体评价:计算群体P(t)中各个个体的适应度。
c)选择运算:将选择运算元作用于群体。选择的目的是把最佳化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的。
d)交叉运算:将交叉运算元作用于群体。遗传算法中起核心作用的就是交叉运算元。
e)变异运算:将变异运算元作用于群体。即是对群体中的个体串的某些基因座上的基因值作变动。群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。
f)终止条件判断:若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
特点
遗传算法是解决搜寻问题的一种通用算法,对于各种通用问题都可以使用。搜寻算法的共同特徵为:
① 首先组成一组候选解
② 依据某些适应性条件测算这些候选解的适应度
③ 根据适应度保留某些候选解,放弃其他候选解
④ 对保留的候选解进行某些操作,生成新的候选解。
在遗传算法中,上述几个特徵以一种特殊的方式组合在一起:基于染色体群的并行搜寻,带有猜测性质的选择操作、交换操作和突变操作。这种特殊的组合方式将遗传算法与其它搜寻算法区别开来。 遗传算法
遗传算法
遗传算法遗传算法还具有以下几方面的特点:
(1)遗传算法从问题解的串集开始搜寻,而不是从单个解开始。这是遗传算法与传统最佳化算法的极大区别。传统最佳化算法是从单个初始值叠代求最优解的;容易误入局部最优解。遗传算法从串集开始搜寻,覆盖面大,利于全局择优。
(2)遗传算法同时处理群体中的多个个体,即对搜寻空间中的多个解进行评估,减少了陷入局部最优解的风险,同时算法本身易于实现并行化。
(3)遗传算法基本上不用搜寻空间的知识或其它辅助信息,而仅用适应度函式值来评估个体,在此基础上进行遗传操作。适应度函式不仅不受连续可微的约束,而且其定义域可以任意设定。这一特点使得遗传算法的套用範围大大扩展。
(4)遗传算法不是採用确定性规则,而是採用机率的变迁规则来指导他的搜寻方向。
(5)具有自组织、自适应和自学习性。遗传算法利用进化过程获得的信息自行组织搜寻时,适应度大的个体具有较高的生存机率,并获得更适应环境的基因结构。
(6)此外,算法本身也可以採用动态自适应技术,在进化过程中自动调整算法控制参数和编码精度,比如使用模糊自适应法。
现状
进入90年代,遗传算法迎来了兴盛发展时期,无论是理论研究还是套用研究都成了十分热门的课题。尤其是遗传算法的套用研究显得格外活跃,不但它的套用领域扩大,而且利用遗传算法进行最佳化和规则学习的能力也显着提高,同时产业套用方面的研究也在摸索之中。此外一些新的理论和方法在套用研究中亦得到了迅速的发展,这些无疑均给遗传算法增添了新的活力。遗传算法的套用研究已从初期的组合最佳化求解扩展到了许多更新、更工程化的套用方面。
随着套用领域的扩展,遗传算法的研究出现了几个引人注目的新动向:一是基于遗传算法的机器学习,这一新的研究课题把遗传算法从历来离散的搜寻空间的最佳化搜寻算法扩展到具有独特的规则生成功能的崭新的机器学习算法。这一新的学习机制对于解决人工智慧中知识获取和知识最佳化精炼的瓶颈难题带来了希望。二是遗传算法正日益和神经网路、模糊推理以及混沌理论等其它智慧型计算方法相互渗透和结合,这对开拓21世纪中新的智慧型计算技术将具有重要的意义。三是并行处理的遗传算法的研究十分活跃。这一研究不仅对遗传算法本身的发展,而且对于新一代智慧型计算机体系结构的研究都是十分重要的。四是遗传算法和另一个称为人工生命的崭新研究领域正不断渗透。所谓人工生命即是用计算机模拟自然界丰富多彩的生命现象,其中生物的自适应、进化和免疫等现象是人工生命的重要研究对象,而遗传算法在这方面将会发挥一定的作用,五是遗传算法和进化规划(Evolution Programming,EP)以及进化策略(Evolution Strategy,ES)等进化计算理论日益结合。EP和ES几乎是和遗传算法同时独立发展起来的,同遗传算法一样,它们也是模拟自然界生物进化机制的智慧型计算方法,即同遗传算法具有相同之处,也有各自的特点。目前,这三者之间的比较研究和彼此结合的探讨正形成热点。
1991年D.Whitey在他的论文中提出了基于邻域交叉的交叉运算元(Adjacency based crossover),这个运算元是特别针对用序号表示基因的个体的交叉,并将其套用到了TSP问题中,通过实验对其进行了验证。D.H.Ackley等提出了随机叠代遗传爬山法(Stochastic Iterated Genetic Hill-climbing,SIGH)採用了一种複杂的机率选举机制,此机制中由m个“投票者”来共同决定新个体的值(m表示群体的大小)。实验结果表明,SIGH与单点交叉、均匀交叉的神经遗传算法相比,所测试的六个函式中有四个表现出更好的性能,而且总体来讲,SIGH比现存的许多算法在求解速度方面更有竞争力。H.Bersini和G.Seront将遗传算法与单一方法(simplex method)结合起来,形成了一种叫单一操作的多亲交叉运算元(simplex crossover),该运算元在根据两个母体以及一个额外的个体产生新个体,事实上他的交叉结果与对三个个体用选举交叉产生的结果一致。同时,文献还将三者交叉运算元与点交叉、均匀交叉做了比较,结果表明,三者交叉运算元比其余两个有更好的性能。
1992年,英国格拉斯哥大学的李耘(Yun Li)指导博士生将基于二进制基因的遗传算法扩展到七进制、十进制、整数、浮点等的基因,以便将遗传算法更有效地套用于模糊参量,系统结构等的直接最佳化,于1997年开发了可能是世界上最受欢迎的、也是最早之一的遗传/进化算法的网上程式 EA_demo,以帮助新手线上互动式了解进化计算的编码和工作原理,并在格拉斯哥召开第二届IEE/IEEE遗传算法套用国际会议,于2000年组织了由遗传编程(Genetic Programming)发明人斯坦福的 John Koza 等参加的 EvoNet 研讨会,探索融合GA与GP结构寻优,超越固定结构和数值最佳化的局限性。
国内也有不少的专家和学者对遗传算法的交叉运算元进行改进。2002年,戴晓明等套用多种群遗传并行进化的思想,对不同种群基于不同的遗传策略,如变异机率,不同的变异运算元等来搜寻变数空间,并利用种群间迁移运算元来进行遗传信息交流,以解决经典遗传算法的收敛到局部最优值问题
2004年,赵宏立等针对简单遗传算法在较大规模组合最佳化问题上搜寻效率不高的现象,提出了一种用基因块编码的并行遗传算法(Building-block Coded Parallel GA,BCPGA)。该方法以粗粒度并行遗传算法为基本框架,在染色体群体中识别出可能的基因块,然后用基因块作为新的基因单位对染色体重新编码,产生长度较短的染色体,在用重新编码的染色体群体作为下一轮以相同方式演化的初始群体。
2005年,江雷等针对并行遗传算法求解TSP问题,探讨了使用弹性策略来维持群体的多样性,使得算法跨过局部收敛的障碍,向全局最优解方向进化。
基本框架
编码
遗传算法不能直接处理问题空间的参数,必须把它们转换成遗传空间的由基因按一定结构组成的染色体或个体。这一转换操作就叫做编码,也可以称作(问题的)表示(representation)。
评估编码策略常採用以下3个规範: 遗传算法
遗传算法
遗传算法a)完备性(completeness):问题空间中的所有点(候选解)都能作为GA空间中的点(染色体)表现。
b)健全性(soundness): GA空间中的染色体能对应所有问题空间中的候选解。
c)非冗余性(nonredundancy):染色体和候选解一一对应。
目前的几种常用的编码技术有二进制编码,浮点数编码,字元编码,变成编码等。
而二进制编码是目前遗传算法中最常用的编码方法。即是由二进制字元集{0,1}产生通常的0,1字元串来表示问题空间的候选解。它具有以下特点:
a)简单易行
b)符合最小字元集编码原则
c)便于用模式定理进行分析,因为模式定理就是以基础的。
适应度函式
进化论中的适应度,是表示某一个体对环境的适应能力,也表示该个体繁殖后代的能力。遗传算法的适应度函式也叫评价函式,是用来判断群体中的个体的优劣程度的指标,它是根据所求问题的目标函式来进行评估的。
遗传算法在搜寻进化过程中一般不需要其他外部信息,仅用评估函式来评估个体或解的优劣,并作为以后遗传操作的依据。由于遗传算法中,适应度函式要比较排序并在此基础上计算选择机率,所以适应度函式的值要取正值。由此可见,在不少场合,将目标函式映射成求最大值形式且函式值非负的适应度函式是必要的。
适应度函式的设计主要满足以下条件:
a)单值、连续、非负、最大化
b) 合理、一致性
c)计算量小
d)通用性强。
在具体套用中,适应度函式的设计要结合求解问题本身的要求而定。适应度函式设计直接影响到遗传算法的性能。
初始群体选取
遗传算法中初始群体中的个体是随机产生的。一般来讲,初始群体的设定可採取如下的策略:
a)根据问题固有知识,设法把握最优解所占空间在整个问题空间中的分布範围,然后,在此分布範围内设定初始群体。
b)先随机生成一定数目的个体,然后从中挑出最好的个体加到初始群体中。这种过程不断叠代,直到初始群体中个体数达到了预先确定的规模。
一般算法
遗传算法是基于生物学的,理解或编程都不太难。下面是遗传算法的一般算法:
建初始状态
初始种群是从解中随机选择出来的,将这些解比喻为染色体或基因,该种群被称为第一代,这和符号人工智慧系统的情况不一样,在那里问题的初始状态已经给定了。
评估适应度
对每一个解(染色体)指定一个适应度的值,根据问题求解的实际接近程度来指定(以便逼近求解问题的答案)。不要把这些“解”与问题的“答案”混为一谈,可以把它理解成为要得到答案,系统可能需要利用的那些特性。
繁殖
繁殖(包括子代突变)
带有较高适应度值的那些染色体更可能产生后代(后代产生后也将发生突变)。后代是父母的产物,他们由来自父母的基因结合而成,这个过程被称为“杂交”。
下一代
如果新的一代包含一个解,能产生一个充分接近或等于期望答案的输出,那幺问题就已经解决了。如果情况并非如此,新的一代将重複他们父母所进行的繁衍过程,一代一代演化下去,直到达到期望的解为止。
并行计算
非常容易将遗传算法用到并行计算和群集环境中。一种方法是直接把每个节点当成一个并行的种群看待。然后有机体根据不同的繁殖方法从一个节点迁移到另一个节点。另一种方法是“农场主/劳工”体系结构,指定一个节点为“农场主”节点,负责选择有机体和分派适应度的值,另外的节点作为“劳工”节点,负责重新组合、变异和适应度函式的评估。
术语说明
由于遗传算法是由进化论和遗传学机理而产生的搜寻算法,所以在这个算法中会用到很多生物遗传学知识,下面是我们将会用来的一些术语说明:
染色体
染色体又可以叫做基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小。
基因
基因是串中的元素,基因用于表示个体的特徵。例如有一个串S=1011,则其中的1,0,1,1这4个元素分别称为基因。它们的值称为等位基因(Alleles)。
基因位点
基因位点在算法中表示一个基因在串中的位置称为基因位置(Gene Position),有时也简称基因位。基因位置由串的左向右计算,例如在串 S=1101 中,0的基因位置是3。
特徵值
在用串表示整数时,基因的特徵值与二进制数的权一致;例如在串 S=1011 中,基因位置3中的1,它的基因特徵值为2;基因位置1中的1,它的基因特徵值为8。
适应度
各个个体对环境的适应程度叫做适应度(fitness)。为了体现染色体的适应能力,引入了对问题中的每一个染色体都能进行度量的函式,叫适应度函式。 这个函式是计算个体在群体中被使用的机率。
运算过程
遗传操作是模拟生物基因遗传的做法。在遗传算法中,通过编码组成初始群体后,遗传操作的任务就是对群体的个体按照它们对环境适应度(适应度评估)施加一定的操作,从而实现优胜劣汰的进化过程。从最佳化搜寻的角度而言,遗传操作可使问题的解,一代又一代地最佳化,并逼近最优解。 遗传过程
遗传过程
遗传过程遗传操作包括以下三个基本遗传运算元(genetic operator):选择(selection);交叉(crossover);变异(mutation)。这三个遗传运算元有如下特点:
个体遗传运算元的操作都是在随机扰动情况下进行的。因此,群体中个体向最优解迁移的规则是随机的。需要强调的是,这种随机化操作和传统的随机搜寻方法是有区别的。遗传操作进行的高效有向的搜寻而不是如一般随机搜寻方法所进行的无向搜寻。
遗传操作的效果和上述三个遗传运算元所取的操作机率,编码方法,群体大小,初始群体以及适应度函式的设定密切相关。
选择
从群体中选择优胜的个体,淘汰劣质个体的操作叫选择。选择运算元有时又称为再生运算元(reproduction operator)。选择的目的是把最佳化的个体(或解)直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的,目前常用的选择运算元有以下几种:适应度比例方法、随机遍历抽样法、局部选择法。 遗传算法
遗传算法
遗传算法其中轮盘赌选择法 (roulette wheel selection)是最简单也是最常用的选择方法。在该方法中,各个个体的选择机率和其适应度值成比例。设群体大小为n,其中个体i的适应度为,则i 被选择的机率,为遗传算法
显然,机率反映了个体i的适应度在整个群体的个体适应度总和中所占的比例。个体适应度越大。其被选择的机率就越高、反之亦然。计算出群体中各个个体的选择机率后,为了选择交配个体,需要进行多轮选择。每一轮产生一个[0,1]之间均匀随机数,将该随机数作为选择指针来确定被选个体。个体被选后,可随机地组成交配对,以供后面的交叉操作。
交叉
在自然界生物进化过程中起核心作用的是生物遗传基因的重组(加上变异)。同样,遗传算法中起核心作用的是遗传操作的交叉运算元。所谓交叉是指把两个父代个体的部分结构加以替换重组而生成新个体的操作。通过交叉,遗传算法的搜寻能力得以飞跃提高。
交叉运算元根据交叉率将种群中的两个个体随机地交换某些基因,能够产生新的基因组合,期望将有益基因组合在一起。根据编码表示方法的不同,可以有以下的算法:
a)实值重组(real valued recombination)
1)离散重组(discrete recombination)
2)中间重组(intermediate recombination)
3)线性重组(linear recombination)
4)扩展线性重组(extended linear recombination)。
b)二进制交叉(binary valued crossover)
1)单点交叉(single-point crossover)
2)多点交叉(multiple-point crossover)
3)均匀交叉(uniform crossover)
4)洗牌交叉(shuffle crossover)
5)缩小代理交叉(crossover with reduced surrogate)。
最常用的交叉运算元为单点交叉(one-point crossover)。具体操作是:在个体串中随机设定一个交叉点,实行交叉时,该点前或后的两个个体的部分结构进行互换,并生成两个新个体。下面给出了单点交叉的一个例子:
个体A:1 0 0 1 ↑1 1 1 → 1 0 0 1 0 0 0 新个体
个体B:0 0 1 1 ↑0 0 0 → 0 0 1 1 1 1 1 新个体
变异
变异运算元的基本内容是对群体中的个体串的某些基因座上的基因值作变动。依据个体编码表示方法的不同,可以有以下的算法:
a)实值变异
b)二进制变异。
一般来说,变异运算元操作的基本步骤如下:
a)对群中所有个体以事先设定的变异机率判断是否进行变异
b)对进行变异的个体随机选择变异位进行变异。
遗传算法引入变异的目的有两个:一是使遗传算法具有局部的随机搜寻能力。当遗传算法通过交叉运算元已接近最优解邻域时,利用变异运算元的这种局部随机搜寻能力可以加速向最优解收敛。显然,此种情况下的变异机率应取较小值,否则接近最优解的积木块会因变异而遭到破坏。二是使遗传算法可维持群体多样性,以防止出现未成熟收敛现象。此时收敛机率应取较大值。
遗传算法中,交叉运算元因其全局搜寻能力而作为主要运算元,变异运算元因其局部搜寻能力而作为辅助运算元。遗传算法通过交叉和变异这对相互配合又相互竞争的操作而使其具备兼顾全局和局部的均衡搜寻能力。所谓相互配合.是指当群体在进化中陷于搜寻空间中某个超平面而仅靠交叉不能摆脱时,通过变异操作可有助于这种摆脱。所谓相互竞争,是指当通过交叉已形成所期望的积木块时,变异操作有可能破坏这些积木块。如何有效地配合使用交叉和变异操作,是目前遗传算法的一个重要研究内容。
基本变异运算元是指对群体中的个体码串随机挑选一个或多个基因座并对这些基因座的基因值做变动(以变异机率P.做变动),(0,1)二值码串中的基本变异操作如下:
基因位下方标有*号的基因发生变异。
变异率的选取一般受种群大小、染色体长度等因素的影响,通常选取很小的值,一般取0.001-0.1。 遗传算法
遗传算法
遗传算法终止条件
当最优个体的适应度达到给定的阈值,或者最优个体的适应度和群体适应度不再上升时,或者叠代次数达到预设的代数时,算法终止。预设的代数一般设定为100-500代。
不足之处
(1)编码不规範及编码存在表示的不準确性。
(2)单一的遗传算法编码不能全面地将最佳化问题的约束表示出来。考虑约束的一个方法就是对不可行解採用阈值,这样,计算的时间必然增加。
(3)遗传算法通常的效率比其他传统的最佳化方法低。
(4)遗传算法容易过早收敛。
(5)遗传算法对算法的精度、可行度、计算複杂性等方面,还没有有效的定量分析方法。
套用
由于遗传算法的整体搜寻策略和最佳化搜寻方法在计算时不依赖于梯度信息或其它辅助知识,而只需要影响搜寻方向的目标函式和相应的适应度函式,所以遗传算法提供了一种求解複杂系统问题的通用框架,它不依赖于问题的具体领域,对问题的种类有很强的鲁棒性,所以广泛套用于许多科学,下面我们将介绍遗传算法的一些主要套用领域:
函式最佳化
函式最佳化是遗传算法的经典套用领域,也是遗传算法进行性能评价的常用算例,许多人构造出了各种各样複杂形式的测试函式:连续函式和离散函式、凸函式和凹函式、低维函式和高维函式、单峰函式和多峰函式等。对于一些非线性、多模型、多目标的函式最佳化问题,用其它最佳化方法较难求解,而遗传算法可以方便的得到较好的结果。
组合最佳化
随着问题规模的增大,组合最佳化问题的搜寻空间也急剧增大,有时在目前的计算上用枚举法很难求出最优解。对这类複杂的问题,人们已经意识到应把主要精力放在寻求满意解上,而遗传算法是寻求这种满意解的最佳工具之一。实践证明,遗传算法对于组合最佳化中的NP问题非常有效。例如遗传算法已经在求解旅行商问题、 背包问题、装箱问题、图形划分问题等方面得到成功的套用。
此外,GA也在生产调度问题、自动控制、机器人学、图象处理、人工生命、遗传编码和机器学习等方面获得了广泛的运用。
车间调度
车间调度问题是一个典型的NP-Hard问题,遗传算法作为一种经典的智慧型算法广泛用于车间调度中,很多学者都致力于用遗传算法解决车间调度问题,现今也取得了十分丰硕的成果。从最初的传统车间调度(JSP)问题到柔性作业车间调度问题(FJSP),遗传算法都有优异的表现,在很多算例中都得到了最优或近优解。
演示学习
EA_demo,英国格拉斯哥大学1997年出版,至今仍广泛使用,採用大学包括英国利物浦(Liverpool)大学、苏塞克斯(Sussex)大学、北安普顿(Northampton)大学,德国乌尔姆(Ulm)大学,瑞士日内瓦(Geneva)大学,西班牙格瑞那达(Granada)大学,葡萄牙新里斯本(Nova de Lisboa)大学,美国加州大学戴维斯分校(UC Davies),加拿大卡尔加里(Calgary)大学,澳大利亚墨尔本皇家理工大学(RMIT),新加坡国立大学,台湾国立清华大学,上海交通大学,巴西PUCRS大学等。
EA_demo允许用户直接在网页上一代一代地手动运行,以看遗传/进化算法是怎样一步一步操作的,亦可在背景中批次运行,以观察算法的收敛和染色体是否跳出局部最优。用户可以改变终止代数,群体规模,交配率,变异率和选择机制。也有其它自学课件收录于AI中心网站和欧洲软计算中心网站。
转载请注明出处海之美文 » 遗传算法(生物进化过程的计算模型)